前回、RTX 2080 を試しに機械学習に使ってみたら CPU の18倍ほど高速で幸せになれました。
一方、Amazon でも Google でも Microsoft でもメジャーなクラウドプロバイダならどこでも機械学習のクラウドサービスを提供しています。
それらと比較した場合、ローカル PC + GeForce RTX 2080 での機械学習環境は、計算スピードの面でどうなのでしょうか?
とりあえず、今回は有名どころで Amazon から試してみました。
Amazon SageMaker
AWS で機械学習をするのに、EC2 や Docker上で Python 環境を設定して機械学習に使うこともできます。ですがそれだと、環境設定などすべてを自分でしないといけないのと、また GPU を搭載した高価なインスタンスを EC2 でインタラクティブに使うとなると、お金も余分にかかります
一方、機械学習のための Amazon SageMaker というサービスがあります。これだと最初から機械学習のために設定された環境が提供されており、Jupyter Notebook でインタラクティブに実行させたり、バッチジョブとして機械学習トレーニング計算を走らせたり、学習後のモデルにエンドポイントを付けてサービスとして公開などもできます。
また、ノートブック用のインスタンスと、モデルのトレーニングジョブ用のインスタンスなどを別途指定できるので、長時間利用するであろうノートブック用は安いインスタンスで、またトレーニング計算のジョブだけ GPU インスタンスで、などと切り替えられます。トレーニングジョブは秒単位で課金され、終了後も自動的に停止するので、最小限の料金で GPU インスタンスを利用することができます。
初めて利用する場合は無料利用枠が付いてきます。
Amazon SageMaker の使用を無料で開始できます。Amazon SageMaker では、サインアップ後最初の 2 か月間、モデル構築のための notebook 利用に t2.medium インスタンスを 1 か月あたり 250 時間、トレーニングに m4.xlarge インスタンスを 50 時間、リアルタイム推論とバッチ変換用の機械学習モデルのデプロイに m4.xlarge インスタンスを合計で 125 時間、無料でご利用いただけます。無料利用枠は、初めて SageMaker リソースを作成した最初の月から始まります。
残念ながら GPU インスタンスは無料枠には付いていないので、とりあえずは無料枠から始めてみます。
まずはノートブック上 (t2.medium) で学習させてみる
無料枠では、t2.medium をノートブック利用に使えます。
- vCPU x 2
- メモリ 4 GiB
一番手軽なのは、MNIST のサンプルプログラム をそのままノートブックにコピペして実行する方法です。
こんな感じ。
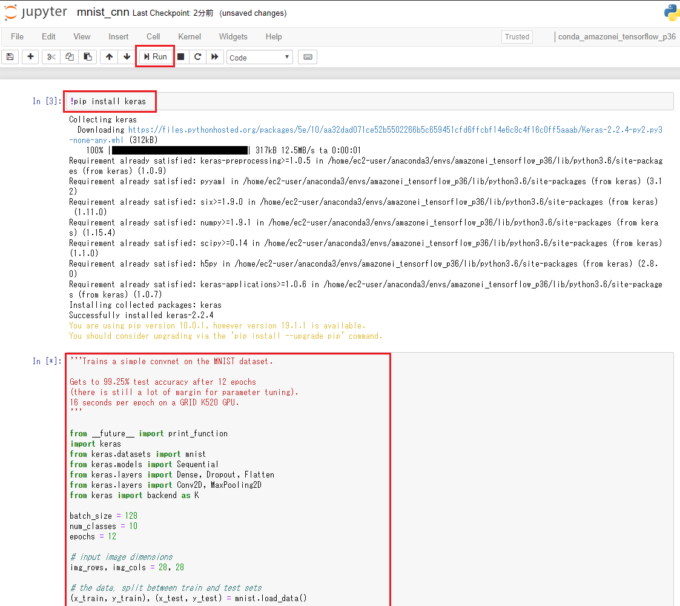
Keras がないと怒られたので、”!pip install keras” を実行した後、サンプルプログラムをそのままコピペし、実行ボタンを押すだけです。
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
60000/60000 [==============================] - 117s 2ms/step - loss: 0.2570 - acc: 0.9200 - val_loss: 0.0610 - val_acc: 0.9820
Epoch 2/12
60000/60000 [==============================] - 369s 6ms/step - loss: 0.0882 - acc: 0.9740 - val_loss: 0.0401 - val_acc: 0.9865
Epoch 3/12
60000/60000 [==============================] - 327s 5ms/step - loss: 0.0668 - acc: 0.9798 - val_loss: 0.0381 - val_acc: 0.9874
...
1 Epoch 計算あたりの時間は117秒~369秒と大きくバラついていますね。
前回当方のパソコンの CPU i7-8086k (6コア/12スレッド 4GHz) だけで計算させた場合 で 1 Epoch 56秒程度だったので、それよりは大分遅いです。
ですが vCPU=2 ということを考えればこんなものでしょうか。要はノートブックは手軽だけど計算速度は期待するなということですね。
次に無料枠で付いてきた ml.m4.xlarge で学習させてみる
より強力な ml.m4.xlarge インスタンスを、無料枠でトレーニングに 50 時間使えるので、これでも実験してみます。
- 4 vCPU
- 16 GiB
- 1時間あたり 0.361 USD
そのためには、Keras の MNIST サンプルプログラムを、以下のページを参考にして3つに分解しました。

- 機械学習トレーニングジョブで走るスクリプト本体(ファイルシステムに置いておく)
- 学習データを取得し、S3 にアップロード(ノートブックから実行)
- 機械学習トレーニングジョブを投入するコマンド(ノートブックから実行)
最後のジョブ投入コマンドは以下のような感じ(amazon 説明文そのまま)で、”train_instance_type” というパラメータを今回は “ml.m4.xlarge” としておきます。
from sagemaker.tensorflow import TensorFlow
from sagemaker import get_execution_role
role = get_execution_role()
estimator = TensorFlow(
entry_point = "./mnist_cnn_sagemaker.py",
role=role,
train_instance_count=1,
train_instance_type="ml.m4.xlarge",
#train_instance_type="ml.p2.xlarge",
framework_version="1.12.0",
py_version='py3',
script_mode=True,
hyperparameters={'batch-size': 128,
'num-classes': 10,
'epochs': 3})
estimator.fit(input_data)
結果はこちらです。
Using TensorFlow backend.
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
...
60000/60000 [==============================] - 61s 1ms/step - loss: 0.0656 - acc: 0.9805 - val_loss: 0.0356 - val_acc: 0.9874
Test loss: 0.03555023465531412
Test accuracy: 0.9874
1 Epoch 計算あたり 61秒かかっています。
ちなみに、前回うちのパソコン i7-8086k で CPU だけで計算させた場合 (1 Epoch 56秒) よりも多少遅いぐらいです。
いよいよ GPU インスタンス ml.p2.xlarge を利用してみる
ml.p2.xlarge のスペックは以下の通りです。
- vCPU = 4
- Memory = 61 (GB)
- GPU = Tesla K80
- GPU Memory = 12 (GB)
- 1時間あたり 2.159 USD
先ほどの計算ジョブ投入のスクリプトで、”train_instance_type” のパラメータを変えれば簡単にインスタンスを変更できます。
・・・できる予定でしたが、ml.p2.xlarge を指定するとエラーが出てしまいます。
ResourceLimitExceeded: An error occurred (ResourceLimitExceeded) when calling the CreateTrainingJob operation: The account-level service limit ‘ml.p2.xlarge for training job usage’ is 0 Instances, with current utilization of 0 Instances and a request delta of 1 Instances. Please contact AWS support to request an increase for this limit.
なんでも、デフォルトでは使えるリソースにある程度制限がかかっているようなので、amazon のサポート に連絡して解除してもらう必要があります。
さて、リミットを解除してもらったら、気を取り直して再度実行してみます。
SM_NUM_CPUS=4
SM_NUM_GPUS=1
...
SM_HP_BATCH-SIZE=128
SM_HP_NUM-CLASSES=10
SM_HP_MODEL_DIR=s3://sagemaker-ap-northeast-1-144034390085/sagemaker-tensorflow-scriptmode-2019-05-17-21-05-01-769/model
SM_HP_EPOCHS=3
PYTHONPATH=/opt/ml/code:/usr/local/bin:/usr/lib/python36.zip:/usr/lib/python3.6:/usr/lib/python3.6/lib-dynload:/usr/local/lib/python3.6/dist-packages:/usr/lib/python3/dist-packages
Invoking script with the following command:
/usr/bin/python mnist_cnn_sagemaker.py --batch-size 128 --epochs 3 --model_dir s3://sagemaker-ap-northeast-1-144034390085/sagemaker-tensorflow-scriptmode-2019-05-17-21-05-01-769/model --num-classes 10
なるほど、トレーニングジョブとは、このようなコマンドラインで起動されるわけですね。
ちゃんと CPU=4, GPU=1 の環境になっており、先ほどトリガで指定したハイパーパラメータが渡されています。
Using TensorFlow backend.
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/3
60000/60000 [==============================] - 11s 187us/step - loss: 0.2679 - acc: 0.9179 - val_loss: 0.0546 - val_acc: 0.9840
Epoch 2/3
60000/60000 [==============================] - 8s 130us/step - loss: 0.0878 - acc: 0.9740 - val_loss: 0.0424 - val_acc: 0.9861
Epoch 3/3
60000/60000 [==============================] - 8s 130us/step - loss: 0.0654 - acc: 0.9803 - val_loss: 0.0319 - val_acc: 0.9895
Test loss: 0.03185783924612915
Test accuracy: 0.9895
1 Epoch あたり 8秒 (1 Step 130 マイクロ秒)程度かかっています。
これは・・・。前回うちの RTX 2080 で計算させた場合の 1 Epoch 3秒 (1 step 52マイクロ秒) より 2~3 倍程度遅いではありませんか!
わざわざリミットを解除してもらって、課金してまで GPU インスタンスで実行したのにあまりに残念な結果です。
結論
NVIDIA GeForce RTX 2080 等のゲーミング PC を持っている人なら、クラウドサービスで GPU インスタンスを使うよりも、ローカルに PC で計算させた方がスピードは速いです。
ちなみに今回利用した ml.p2.xlarge は GPU インスタンスとしては旧型、かつ一番安いものでした。もちろんお金に糸目を付けずにもっと高いインスタンスを使えば速くなると思われますが、それだと1時間利用しただけで何千円もしてしまうので、ちょっと個人で趣味に利用するのは厳しそうです・・・。
もっと大規模でより大きな GPU メモリを利用するようなケースでは別かもしれませんが、少なくてもローカルで走らせることができるようなプログラム・データ量なら、わざわざ別途料金を払ってクラウドで計算させなくても良さそうです。