
前回はニューラルネットワークを学習させるのに、Amazon SageMaker で GPU インスタンスを使ってみましたが、ローカル PC で RTX 2080 を使って計算させた方が遙かに速いという結果になりました。
ですが、Google の Colaboratory というサービスが良いという噂を聞いたので、今回はそれと比較してみました。
Google Colaboratory
ウェブブラウザから利用できるクラウド上の Jypyter ノートブック環境です。Tensorflow, Keras, Pandas といった機械学習やデータ解析の環境設定済みなので、Google アカウントがあれば直ぐに使えます。

使い方は本当に簡単です。ウェブサイトにアクセスして、セルに書かれた Python コードをクリックして、実行ボタンを押すだけです。それだけでバックエンドの Google データセンターのサーバに接続されて実行されます。
しかも無料です。
しかも GPU インスタンスまで無料で利用できます。他にも TPU (Tensor Processor Unit) インスタンスも無料で利用できます。
何これ?何の設定も無くめっちゃ簡単に使える。前回 Amazon SageMaker を使うためにインスタンスの作成とか、S3バケットの作成とか、GPU リソース制限解除とか、苦労していたのがアホらしいです。。。
まずはノートブック上で学習実行
前回までの実験との比較のため、MNIST のサンプルプログラム をまた使いました。
ソースコード全体をそのまま Jupyter ノートブックのセルにコピペして、実行ボタンを押すだけです。(あまり長時間学習させてもあまりメリットないので、Epoch 数は 5 としました)
Using TensorFlow backend.
Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
11493376/11490434 [==============================] - 1s 0us/step
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
...
Train on 60000 samples, validate on 10000 samples
Epoch 1/5
60000/60000 [==============================] - 169s 3ms/step - loss: 0.2691 - acc: 0.9176 - val_loss: 0.0712 - val_acc: 0.9764
Epoch 2/5
60000/60000 [==============================] - 168s 3ms/step - loss: 0.0889 - acc: 0.9739 - val_loss: 0.0440 - val_acc: 0.9859
Epoch 3/5
60000/60000 [==============================] - 167s 3ms/step - loss: 0.0646 - acc: 0.9804 - val_loss: 0.0360 - val_acc: 0.9872
Epoch 4/5
60000/60000 [==============================] - 165s 3ms/step - loss: 0.0555 - acc: 0.9839 - val_loss: 0.0336 - val_acc: 0.9896
Epoch 5/5
60000/60000 [==============================] - 168s 3ms/step - loss: 0.0465 - acc: 0.9860 - val_loss: 0.0298 - val_acc: 0.9889
Test loss: 0.029843844765414542
Test accuracy: 0.9889
1 Epoch の実行あたり 165~169秒程度かかっています。
前回、Amazon SageMaker 無料枠のノートブック上で実行した場合は 117~369秒 だったので、大体同じようなスペックの compute node を使っていると推測されます。
GPU で実行
さて、メニューに行ってみると、なんと本当にランタイム環境で GPU インスタンスを指定できるではないですか!無料なのにいいのですか?
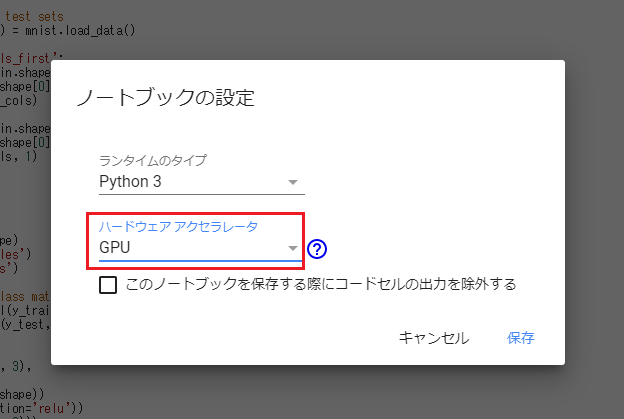
注:連続して利用できる時間には限りがあるようです。
そして GPU インスタンスにつなげた状態で同じく実行してみた結果です。
Using TensorFlow backend.
Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
11493376/11490434 [==============================] - 0s 0us/step
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
...
Train on 60000 samples, validate on 10000 samples
Epoch 1/5
60000/60000 [==============================] - 10s 169us/step - loss: 0.2662 - acc: 0.9164 - val_loss: 0.0583 - val_acc: 0.9813
Epoch 2/5
60000/60000 [==============================] - 5s 79us/step - loss: 0.0915 - acc: 0.9725 - val_loss: 0.0395 - val_acc: 0.9874
Epoch 3/5
60000/60000 [==============================] - 5s 80us/step - loss: 0.0683 - acc: 0.9797 - val_loss: 0.0384 - val_acc: 0.9870
Epoch 4/5
60000/60000 [==============================] - 5s 77us/step - loss: 0.0565 - acc: 0.9827 - val_loss: 0.0289 - val_acc: 0.9908
Epoch 5/5
60000/60000 [==============================] - 5s 77us/step - loss: 0.0462 - acc: 0.9864 - val_loss: 0.0267 - val_acc: 0.9909
Test loss: 0.026692246038156738
Test accuracy: 0.9909
1 Epoch あたり約5秒(1 step 77 マイクロ秒)程度かかっています。これは・・・ ローカル PC の GeForce RTX 2080 で計算させた場合の 1 Epoch 約3秒 (1 step 52マイクロ秒)よりは 1.5倍程度遅いですが、Amazon で課金して使った ml.p2.xlarge (GPU = Tesla K80) の1Epoch 8秒よりも断然速いではないですか!
TPU ランタイムではどうなる?
ちなみにランタイムの選択のところで、「TPU」を選ぶこともできます。これはディープラーニングのために特化された Tensor Processing Unit というやつですね。
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
...
Train on 60000 samples, validate on 10000 samples
Epoch 1/5
60000/60000 [==============================] - 166s 3ms/step - loss: 0.2706 - acc: 0.9173 - val_loss: 0.0589 - val_acc: 0.9818
Epoch 2/5
60000/60000 [==============================] - 164s 3ms/step - loss: 0.0939 - acc: 0.9722 - val_loss: 0.0427 - val_acc: 0.9861
Epoch 3/5
60000/60000 [==============================] - 164s 3ms/step - loss: 0.0668 - acc: 0.9800 - val_loss: 0.0354 - val_acc: 0.9882
Epoch 4/5
60000/60000 [==============================] - 164s 3ms/step - loss: 0.0558 - acc: 0.9838 - val_loss: 0.0346 - val_acc: 0.9886
Epoch 5/5
60000/60000 [==============================] - 166s 3ms/step - loss: 0.0480 - acc: 0.9854 - val_loss: 0.0324 - val_acc: 0.9901
Test loss: 0.03241487098003854
Test accuracy: 0.9901
んん・・・? 遅い。 1 Epoch 165秒ぐらいというと、最初に通常のインスタンスで計算させたときと変わらないですね。
ということは、TPU は利用されておらず、CPU のみで計算されていると推測されます。
ググってみたところ、TPU を利用するためには少しコードを変更する必要があるようです。まぁそれは後日試してみます。
結論
やはり、Geforce RTX 2080 等のゲーミング PC を持っている人は、クラウド機械学習サービスを使うよりも、自分の PC で計算させた方が高速にディープラーニング学習ができそうです。
とはいえ、そこまでのスペックの PC を持っていない人、もしくはタブレットやスマホからも機械学習環境にアクセスしたい人などは、Google Colaboratory はそこそこ速くすごく便利です。しかも Google Drive などとも連携できるので、15GB までのデータストーレージなら無料で利用できます。
なんでこんなサービスが無料で利用できるの謎ですが、企業でデータや知的財産の制限があるのでなければ、個人的な趣味利用であれば大いにオススメです。